
[AI] How I stopped making three grocery trips a week
/ 6 min read
Table of Contents
Meal prepping was becoming like that one annoying task that kept showing up every weekend but was a complete necessity to have a good productive week. The planning was tedious, but the real bother was constantly forgetting random ingredients – that one squash, green beans, edamame, or even basic stuff like yogurt. Multiple grocery runs per week became the norm. I tried maintaining an Excel sheet, but manually piecing together ingredient lists was still a pain.
So I spent a weekend vibe coding an AI meal planning app. Simple goal: calendar UI for weekly meal input, macro/nutrition breakdown page, and the ability to tweak everything to hit my targets. But the more I used it, the more I realized I was typing similar meals repeatedly – “matar paneer with rice,” “matar paneer with naan” and the AI was processing them from scratch each time, missing obvious ingredient similarities. That’s when I added semantic recipe search with vector embeddings. Now when I type “banana overnight oats”, the app instantly recognizes it’s similar to my previous “strawberry overnight oats” and adapts the ingredient list in milliseconds instead of processing it fresh. Game changer.
The Tech Stack
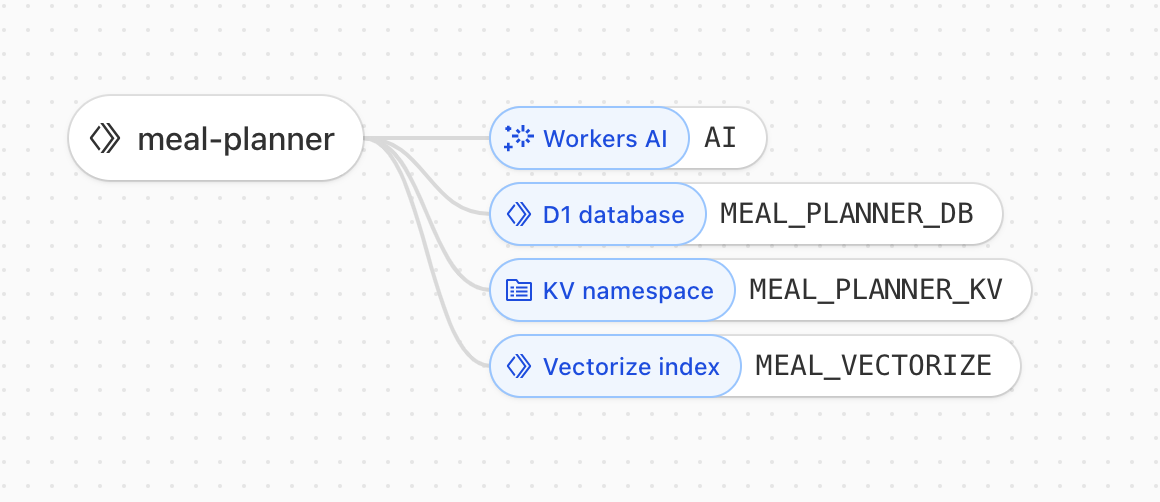
Built this entirely on Cloudflare because I work there and it’s very quick to build on.
Cloudflare Workers handles all the API logic. No cold starts and supports quick deployments. Each worker function processes meal requests, handles ingredient parsing, and manages the session based nutrition tracking. The coolest thing for me though was how easy it is to add all the bells and whistles as bindings. Workers AI is just a configuration to the application as is D1 and KV. Can it be any easier?!
The Two-Layer Cache Strategy
I built a cascading cache system that gets smarter with each meal:
Cloudflare KV for exact meal matches. When I type “paneer tikka masala” for the hundredth time, instant ingredient list. Still hitting ~80% cache rate here.
Cloudflare Vectorize for semantic similarity. When I type “matar paneer with rice,” it finds my previous “matar paneer with naan” embedding and adapts the spices and naan instead of starting from scratch. Catches another ~15% of my queries.
# store meal and ingredients into vectorizeasync function storeMealInVectorize(env: Env, sessionId: string, mealText: string, ingredients: string): Promise<void> { try { const embedding = await generateMealEmbedding(env, mealText); const vectorId = await crypto.subtle.digest('SHA-256', new TextEncoder().encode(`${sessionId}:${mealText}`)) .then(hash => Array.from(new Uint8Array(hash.slice(0, 16))).map(b => b.toString(16).padStart(2, '0')).join(''));
await env.MEAL_VECTORIZE.upsert([{ id: vectorId, values: embedding, metadata: { sessionId: sessionId, mealText: mealText, ingredients: ingredients, timestamp: Date.now() } }]); } catch (error) { }}
# find similar meals from vectorizeasync function findSimilarMeal(env: Env, sessionId: string, mealText: string, threshold: number = 0.9): Promise<{mealText: string, ingredients: string, similarity: number} | null> { try { const embedding = await generateMealEmbedding(env, mealText);
const results = await env.MEAL_VECTORIZE.query(embedding, { topK: 5, returnMetadata: 'all' });
if (results.matches && results.matches.length > 0) { const bestMatch = results.matches[0];
if (bestMatch.score >= threshold && bestMatch.metadata) { return { mealText: bestMatch.metadata.mealText as string, ingredients: bestMatch.metadata.ingredients as string, similarity: bestMatch.score }; } }
return null; } catch (error) { console.error('Failed to search Vectorize:', error); return null; }}D1 (SQLite at the edge) stores all the historical nutrition insights and session data. Each meal plan gets a session ID, and I’m tracking macro trends over time. The cool part is D1’s distributed SQLite setup – I can run complex queries on nutrition data without the overhead of traditional databases. Schema includes session tracking, meal history, and aggregated macro calculations.
Workers AI handles the ingredient extraction and meal parsing. Instead of hitting external APIs, I’m using Cloudflare’s inference network. The latency is good enough – like a minute for complex meal breakdowns. I’m primarily using their text models to parse natural language meal descriptions into structured ingredient lists with quantities.
async function callWorkerAI(env: Env, prompt: string, systemPrompt: string, maxTokens: number = 1000): Promise<string> { const response = await env.AI.run('@cf/meta/llama-3.3-70b-instruct-fp8-fast', { messages: [ { role: 'system', content: systemPrompt }, { role: 'user', content: prompt } ], max_tokens: maxTokens, temperature: 0 }, { gateway: { id: 'meal-planner-gateway' } }); return response.response;}AI Gateway logs everything and gives me observability I didn’t know I needed. Rate limiting, caching strategies, and request analytics all built in. I can see exactly which ingredient parsing requests are expensive and optimize accordingly. The logging helped me identify that certain meal types (complex Asian dishes) were causing higher token usage, so I adjusted my prompts.
Key Learnings
I realized that recipe similarity isn’t about exact ingredient matches - it’s about understanding preferences and user patterns. A vector database (Cloudflare Vectorize) captures these relationships in ways traditional keyword matching never could. Smart Substitutions: When I enter “vegetable pad thai,” it finds my previous “tofu pad thai” and automatically suggests swapping protein with vegetables while keeping the sauce and other ingredients identical.
Seasonal Intelligence: “Vegetable soup” in winter suggests butternut squash and root vegetables, while the same query in summer recommends zucchini and tomatoes based on embedded seasonal metadata. Cuisine Understanding: The embeddings learn that “tofu tikka masala” and “tofu curry” share more DNA than “tofu tikka masala” and “tofu salad,” even though they all contain tofu. It’s faster and saves me valuable time and resources in recomputing ingredients.
The Flow
User drops their weekly meals into the calendar interface. Workers process each meal through the two layer cache system, checking KV for exact matches, Vectorize for semantic similarity, and then finally makes an inference call to the LLM for genuinely new recipes. Everything gets stored in D1 with a session identifier. The nutrition page pulls from D1 to show macro breakdowns and lets you adjust portions in realtime.
While this is a very simplistic view of macro definitions, it works for me and maybe I will add additional information at a later stage. But for now, this is sufficient.
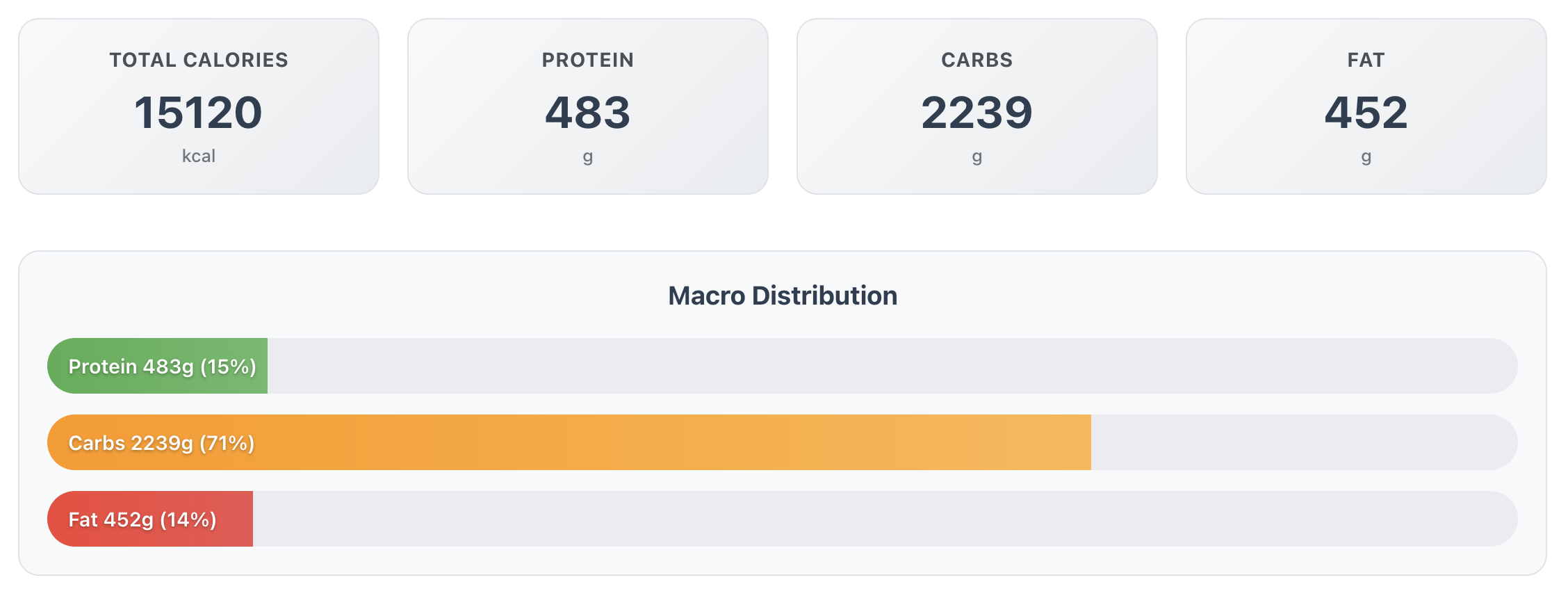
Best part? You just copy paste the final ingredient list. No more forgotten squash.
The whole thing deploys in seconds with wrangler deploy. No infrastructure to manage, no scaling concerns, just pure edge performance. And completely free. Yes, even if you don’t work at Cloudflare, check out our Free tier. You can build a whole lot with just a free account. What I built was probably overkill for a personal project, but the Cloudflare stack made the entire build process ridiculously smooth.